Most websites have navbars with javascript links, which give access to the deeper levels of the site. Typically linkcheckers can't read these links � Xenu included.
Commercial linkcheckers claim to be able to read javascript embedded links, either by �executing� or �parsing� these links.
Parsing means analysing the links found in javascript code, and adding them to the root URL of the scan. Sometimes this does not work, when this relative link path is added to the URL of the page the links are found on � this can lead to incorrect URLs.
Executing avoids this possibility of misconstructed URLs, but takes more time.
Javascript links pose two problems for linkchecking:
There is a workaround for both of these issues !
My solution for this problem has always been to create a simple htm page, to which the navbar links are added as straightforward clickable links. By pushing this file live on your website and using it as the startpage for the Xenu linkscan, all navbar links are included in the scan.
It is important that this new startpage is posted on the site, and not kept on your local computer, otherwise your site will be seen by Xenu as �external�.
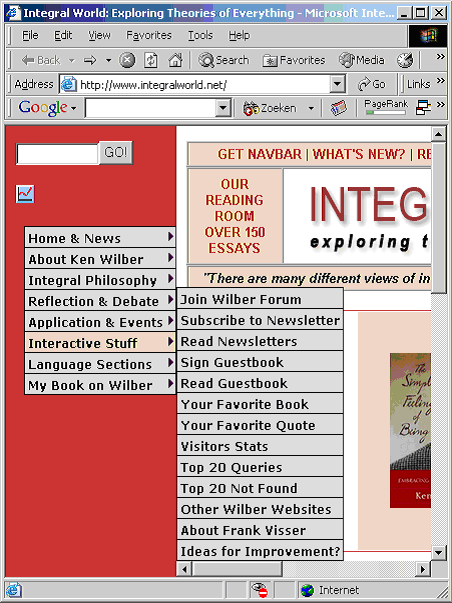
Lets look at an example of a navbar with javascript links, as I have used it on my site integralworld.net:
The links in this navbar are code as:
Menu2_2=new Array("My Visit Reports","http://207.44.196.94/
~wilber/visits.html","",0,20,150,"","","","","","",-1,-1,-1,"","");
�which is impossible for Xenu to recognize as a link. However, when it is recoded like this, Xenu can spider this link without any difficulty:
<a href="http://207.44.196.94/~wilber/visits.html">LINK</a>
This is how a new start page with clickable navbar links would look like:
<html>
<head>
<title>Xenu linkcheck startpage</title>
</head>
<a href="welcome2.html">welcome2.html</a><br>
<a href="biography.html">biography.html</a><br>
<a href="books.html">books.html</a><br>
<a href="readingroom.html">readingroom.html</a><br>
<a href="institute.html">institute.html</a><br>
<a href="kwdp.html">kwdp.html</a><br>
</body>
</html>
or posted on the website, it would look like this:
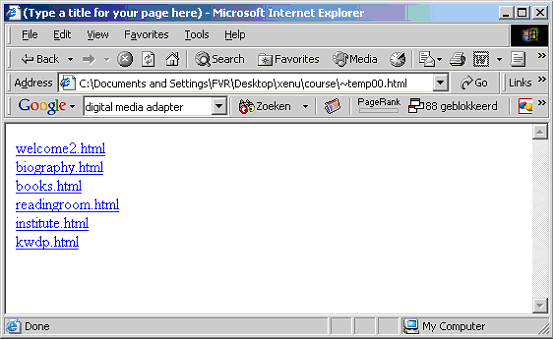
Note: post this linkcheck start page in the same location as your website and start your scan from there, otherwise the scan will fail -- your site will be regarded as external if you have hosted your start page on a different server.
Feel free to add as many links to this start page as you think is necessary to reach the deeper levels of your website.
The second javascript hurdle to take is when they occur on the web pages. Xenu automatically skips these links when scanning a site:
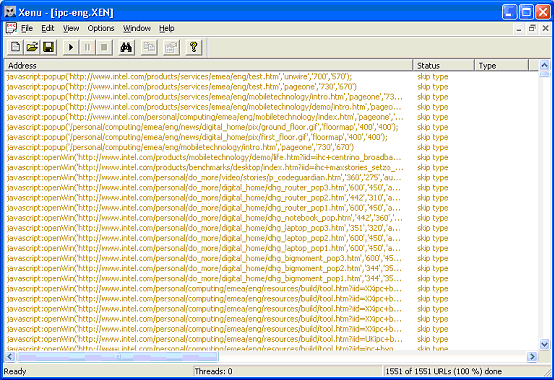
They all get a �skip type� status message.
My solution to this problem has been as follows:
Export the xenu report to a text file, and import this file to Excel. Delete all unnecessary columns, and sort according to Status, so you can find the �skip type� links. Copy these links to a separate worksheet, and sort them according to link name (column A):
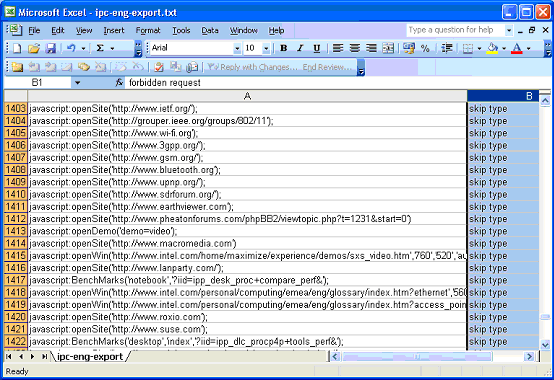
Now copy these URLs (from column A) to a text file in Notepad:
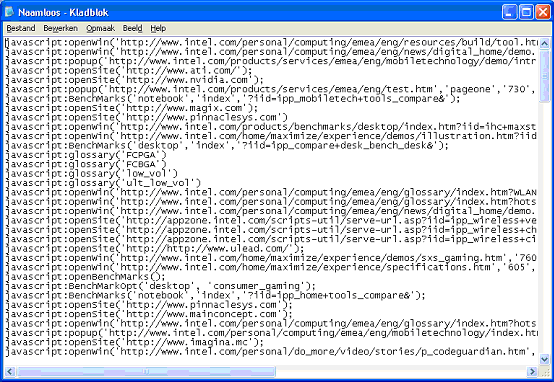
Extract the URLs from this file by stripping the links from the javascript in which they are embedded.
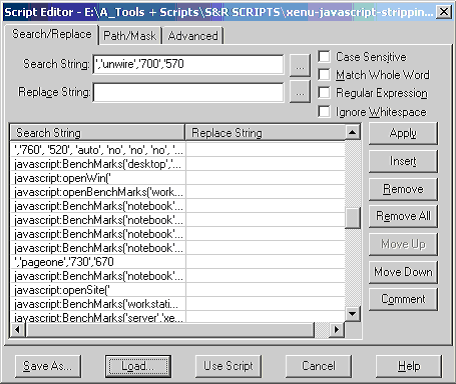
You can write a script that does this for you:
A good program to do that with is Search and Replace from Funduc: http://www.funduc.com/search_replace.htm
Then Check the Javascript-less URLs as described in Chapter 4. Checking a set of links.
Instead of stripping the URLs from all code except the URL proper, it is quicker to use regular expressions to catch the URLs directly.
For example, this regular expression (using Funduc's Search and Replace program), does exactly that:
javascript:*\('(f|h|/)*'*
This regular expression does the following:
The replacement string is:
%2%3
meaning:
When the URL in question is:
javascript:openWin ('http://www.intel.com/personal/computing/emea/fra/glossary/index.htm? enh_int_spe','540','420','no','no','no','no','200','200','glossary');
the regular expression matches exactly with:
http://www.intel.com/personal/computing/emea/fra/glossary/index.htm? enh_int_spe
When the list of javascript links in the text file is cleaned up with this regular expression, it can easily be checked with Xenu.
Hopefully future versions of Xenu will be able to read these javascript links directly, so the connection with the source pages is retained.
Added October 2004
As of version 1.2g (now in it's beta phase) Xenu will be able to handle javascript in links of the type:
It does not matter if the URLs
The only thing you need to do is add this line of code to the .ini file under [Options] (which should be in the same folder as the xenu.exe program is located.):
Javascript=javascript:[_a-zA-Z0-9]+ *\( *['"]([^'"]+)['"]
This regular expression does the following:
The results are really fantastic, all javascript embedded links are now extracted from the javascript and treated as "normal" links -- and scanned.
Added November 2004
To ensure that the only those javascript links are checked that yield a correct URL, it is wise to updgrade your regular expression to:
Javascript=javascript: *[_a-zA-Z0-9]+ *\( *['"]
((/|ftp://|https?://)[^'"]+)['"]
This adds to the original regular expression more precision:
All other javascript links, such as these, are skipped:
Added January 2005
Please note there can be slight variations in the way "javascript:" is written:
To catch all these variations, refine your regex with: [Jj]ava[Ss]cript:
A highly sophisticated regular expression, written by Eugeny Sattler, but currently not supported by Xenu is:
javascript:\w+\s*\(\s*['\"]((?:ftp|https?)://[^'\"]+?)['\"]
(?:\s*,[^,]+?\s*)*\s*\);
See: http://groups.yahoo.com/group/xenu-usergroup/message/102