|
TRANSLATE THIS ARTICLE
Integral World: Exploring Theories of Everything
An independent forum for a critical discussion of the integral philosophy of Ken Wilber
SEE MORE ESSAYS WRITTEN BY DAVID LANE
Random Mutations
in Molecular Biology
Why Ken Wilber's Creationist
Hummer Got Recalled
David Lane & Andrea Diem-Lane
“Neo-Darwinian theory has loopholes large enough to drive several Hummers through.”
—Ken Wilber
“Ken Wilber consistently misrepresents evolution by natural selection.”
—Andrea Diem, Ph.D.
Recently, I received some interesting responses to my article, Frisky Dirty: Why Ken Wilber's New Creationism is Pseudoscience. Each of them, in varying ways, raised objections to current evolutionary theory suggesting that creationists have more ammunition in their arsenal than is usually acknowledged.
I think it is important take such criticisms seriously, even if they have been answered before by molecular biologists. I say this because critics can also help us think anew about a subject and force us to consider different sides to a particular problem or dilemma.
I have discovered in my teaching career that the best way to understand Darwinian evolution is to start with what we know best (ourselves) and then proceed backwards in time by reverse engineering how we came into being.
I remember several years ago when I was invited to explain evolution to a large gathering of Biblical Christians who believed in Creationism. It was a daunting task, but I thought it would be more interesting and more challenging if I upped the ante a bit before I gave my lecture. I looked out at the audience and said, “The problem with evolution is that it makes too much sense. It is probably the most irritating theory developed by man because it explains too much, too simply. For example, T.H. Huxley, later to be more popularly known as Charles Darwin's bulldog, didn't first believe in evolution but later became convinced after reading On the Origin of Species. After which he exclaimed, 'How extremely stupid not to have thought of that!'”
Right then, looking over the sea of smirking faces, I took a risk. “I am going to wager today that the majority of this class will change its mind about Darwin and evolution within an hour. Not because of any rhetorical skill on my part (or lack thereof), but because once the theory is correctly understood, it makes too much empirical and logical sense to ignore it. Yes, the theory is still undergoing corrections and augmentations and, yes, the debate over its finer points is still proceeding in a healthy fashion, but overall the elemental drive of Darwinian evolution holds true."

The gist of that lecture is best captured in my wife Andrea Diem-Lane's small book, Darwin's DNA: A Brief Introduction to Evolutionary Philosophy:
Let's imagine that the young man's name is Shaun. He is 18 years old. The first question we pose is a simple one. Why does Shaun physically look the way he does? Excepting his clothes and hygiene and other personal choices, my students invariably say “because of his parents.”
And that is certainly true and nobody tends to dispute the fact that his parents were the key to his physical looks. But what is it that his parents bring to the equation? The simple answer, of course, is that Shaun's father (let's call him Christopher) contributes sperm whereas his mother (let's call her Catherine) an egg. Both substances are quite small. A human sperm for instance (including both its head and its tail) is roughly 55 microns, so tiny that it is 25,000 times smaller than a golf ball. At this point, we start to see one of the first hallmarks of science and one that is often misunderstood: reductionism. The contribution that Shaun's parents made to their offspring doesn't come at the phenotype level (that is merely the replicating appliance), but rather at the genotype particulate. We have scaled down from a 6”1 body and a 5”4 body to precisely what those larger frames house—a sperm and an egg. Now we have literally “reduced” Shaun's parents to the arena where the information they share is more easily accessible and localized.
One metaphorical way of putting this is to imagine that Christopher and Catherine are individual books, filled with all sorts of historical information. Their desire is to recombine their books and produce a new edition. Since human sexual intercourse is literally the intertwining of two fairly large body forms so that a transmission of information can catalytically induce a viable recombination to occur, we can readily see that what makes a child is essentially the intersecting of binary forms of data.
The larger question that arises in this metaphor (with its real world applications) is how to decipher Catherine's and Christopher's contributions to the book they named Shaun. In what language are their books written? Are they the same language or different? What is the alphabet or rudimentary notation wherein their respective knowledge is inscribed?
Today, unlike in Darwin's day, we can actually answer these queries with remarkable accuracy. Although an egg and a sperm are compositely varied, the essential code they contain is written in a biological language known most famously by its initials: D.N.A. or more properly deoxyribonucleic acid. This language comes in four letters, easily remembered with the acronym C.T.A.G. Here “c” stands for cytosine, “t” for thymine, “a” for adenine, and “g” for guanine.
Thus, Catherine and Christopher shared books which had a common four lettered language. These letters further comprised whole pages numbering in the tens of thousands known as genes which formed twenty-three chapters known as chromosomes. Our entire book is known as a genome.
Shaun is, therefore, the result of two genomes (books) recombined which results in a unified outcome of 25,000 plus genes (pages), 23 chromosomes (chapters), all written in DNA (a four letter alphabet).
Sexual selection, however, is merely the start of why Shaun looks the way he does. Since obviously his mother could have chosen another author to help write her memoirs and in so doing produce a completely different son with a unique set of genes. Shaun isn't merely a duplicate reconfiguring of his parent's deoxyribonucleic acid. Occasionally, when DNA is copied throughout one's body it makes a copying error, what is known as a mutation. This can simply be a one letter change. Instead of ATGGTTTGATGTC, one might get ATGGTTGATTGTC. While at the level of just script it looks somewhat inconsequential, but in terms of applied genetics such minor variations can loom large.
Why mutations occur is a deep subject, but not an insurmountable one, especially if you have an understanding of Heisenberg's uncertainty principle and how quantum mechanics is based on indeterminacy. The introduction of “chance” (or occasional mutations) into the genome is important because it causally explains how a child can indeed be unexpectedly and unpredictably different than his parents. In other words, sexual selection is just one component in what makes up Shaun's physical characteristics. DNA mutations are another. There are two fundamental ways to mutate a gene. The first way is through environmental damage. As the Learn Genetics website, sponsored by Genetic Science Learning Center at the University of Utah, explains:
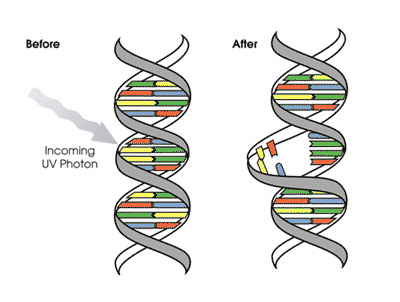
“Ultraviolet light, nuclear radiation, and certain chemicals can damage DNA by altering nucleotide bases so that they look like other nucleotide bases. When the DNA strands are separated and copied, the altered base will pair with an incorrect base and cause a mutation. In the example below a "modified" G now pairs with T, instead of forming a normal pair with C. Environmental agents such as nuclear radiation can damage DNA by breaking the bonds between oxygen (O) and phosphate groups (P). Cells with broken DNA will attempt to fix the broken ends by joining these free ends to other pieces of DNA within the cell. This creates a type of mutation called "translocation." If a translocation breakpoint occurs within or near a gene, that gene's function may be affected.”
The second way is by DNA replication. As the same website elaborates:
“Prior to cell division, each cell must duplicate its entire DNA sequence. This process is called DNA replication. DNA replication begins when a protein called DNA helicase separates the DNA molecule into two strands. Next, a protein called DNA polymerase copies each strand of DNA to create two double-stranded DNA molecules. Mutations result when the DNA polymerase makes a mistake, which happens about once every 100,000,000 bases. Actually, the number of mistakes that remain incorporated into the DNA is even lower than this because cells contain special DNA repair proteins that fix many of the mistakes in the DNA that are caused by mutagens. The repair proteins see which nucleotides are paired incorrectly, and then change the wrong base to the right one.”
Why not postulate the guiding hand of some deity?
However, in a recent letter Dr. Alexander Astin, Allan M. Carter Professor Emeritus of Higher Education and Organizational Change, at the University of California, Los Angeles, raised his deep concerns over random mutations. Professor Astin writes,
“Like every other evolutionist I've talked to or read over the years, Lane finesses the greatest uncertainty in evolutionary theory: the notion of 'random' mutations. Random is simply a fancy way of saying, 'we don't know why it happened.'
In the field of statistics, the word implies that a great many events of a certain type (e.g., coin flips, collapsed wave functions), when viewed in the aggregate, follow a very predictable pattern (with coin flips this pattern would be something like .5 heads). The fact that we don't know why particular mutations occur leaves a gap in evolutionary theory big enough to drive a creationist's truck through, i.e., why not postulate the guiding hand of some deity? And if we put our statistician's hat on, there's no way that the aggregate result of thousands of 'random' mutations ever forms any kind of predictable pattern (e.g., a dandelion, a cockroach, etc.).
This is not to say that the need for evolutionary theory to employ the concept of 'random mutations' proves that the creationists are right, but simply that it leaves plenty of room for intention (or love) to operate.” (January 17th, 2011)
I think there are several issues that need to be unwound in Dr. Astin's assertions. First, we have to be clear about what we mean by a mutation. Properly defined within genetics, “a mutation is a permanent change in the DNA sequence that makes up a gene. Mutations range in size from a single DNA building block (DNA base) to a large segment of a chromosome.”
Second, we need to clarify what we mean by random in this context. The more fundamental feature in DNA replication is its remarkable fidelity. It is that fidelity that must be understood first in order to properly grasp what randomness entails and how it applies to genetic mutations. As Dr. Leslie Pray points out in her fine essay, DNA Replication and Causes of Mutation,
"DNA replication is a truly amazing biological phenomenon. Consider the countless number of times that your cells divide to make you who you are—not just during development, but even now, as a fully mature adult. Then consider that every time a human cell divides and its DNA replicates, it has to copy and transmit the exact same sequence of 3 billion nucleotides to its daughter cells. . . . DNA polymerase enzymes are amazingly particular with respect to their choice of nucleotides during DNA synthesis, ensuring that the bases added to a growing strand are correctly paired with their complements on the template strand (i.e., A's with T's, and C's with G's). Nonetheless, these enzymes do make mistakes at a rate of about 1 per every 100,000 nucleotides. That might not seem like much, until you consider how much DNA a cell has. In humans, with our 6 billion base pairs in each diploid cell, that would amount to about 120,000 mistakes every time a cell divides.”
It is this replicating precision which is the backdrop to understanding varying rates of mutation, not all of which are equal depending on which part of the genome we are addressing in our analysis. Dr. Pray explains,
“Mutation rates vary substantially among taxa, and even among different parts of the genome in a single organism. Scientists have reported mutation rates as low as 1 mistake per 100 million (10-8) to 1 billion (10-9) nucleotides, mostly in bacteria, and as high as 1 mistake per 100 (10-2) to 1,000 (10-3) nucleotides, the latter in a group of error-prone polymerase genes in humans (Johnson et al., 2000).”
In light of this data, it may be more useful to reframe Professor Astin's doubt about randomness and its aggregate possibilities to one about why DNA fidelity, though exceptionally accurate, is not perfect. In other words, why are there replicating changes over time in varying parts of the genome? This is a more focused question and one which has been tackled by a number of scientists worldwide. Miroslav Radman at the Laboratory of Evolutionary and Molecular Genetics in France provides us with one applicable answer in his Nature article "Fidelity and Infidelity":
“John Hopfield and Jacques Ninio introduced the concept of 'kinetic' proofreading to explain the fidelity of molecular processes in which mistakes cannot be identified once they have been made. By delaying formation of the product, erroneous substrates are less likely to be transformed into it. Such mechanisms are seen in protein biosynthesis and may also be involved in presentation of antigens to T-cell receptors. In these cases, high fidelity is gained at the expense of efficiency.
Does nature attempt to achieve perfect fidelity using repair enzymes? Apparently not, because some bacterial mutants have increased fidelity of DNA or protein biosynthesis — an example is so-called StrR mutants, which are resistant to the antibiotic streptomycin. Streptomycin increases the error rate in protein biosynthesis; in its absence, StrR mutants have high fidelity, and grow more slowly than non-mutants. Because fidelity costs, it is optimized rather than maximized. Of course, error rates that are too high can cause death — bacteria and haploid yeast die from a genetic-error catastrophe when their mutation rate is increased 10,000-fold.
There is ample evidence of trade-offs between accuracy and efficacy. In protein synthesis, there are about 3 erroneous amino acids for every 10,000 correct ones; in transcription, about 1 nucleotide per 100,000 is wrong; and in DNA replication, about 1 nucleotide is wrong in every 10 billion. Proteins are functional molecules that are used up, oxidized, broken down and replenished by de novo synthesis. One-third of all proteins synthesized by normal human cells are immediately degraded by proteasomes because they have recognizable folding mistakes. Up to half of all messenger RNAs are erroneous and are therefore broken down. These clean-up systems probably contribute to the functional longevity of non-dividing cells such as neurons and cardiac muscle.
There is a huge investment in the fidelity of DNA replication, because genes are life's database. But when survival is threatened, even DNA fidelity is relaxed. For instance, when bacterial adaptation is limited by the available genetic diversity, genetically unstable populations adapt, at least in the short term, more rapidly than their stable counterparts.
Two classes of genes accelerate genetic variation by enhancing mutation and/or recombination in bacterial populations: stress-inducible wild-type genes and genes whose functional loss increases genetic variability; the former acts on individual cells and the latter on populations. Furthermore, genes encoding proteins under persistent selective pressure, such as a host's immunoglobulin genes or parasite target proteins/genes, show increased mutation rates. Thus, the fidelity of individual genes can be optimized.
There is also a down-to-earth reason for DNA infidelity: DNA replication itself! A top-fidelity DNA-copying machine, such as the DNA-replication complex, can only copy chemically perfect DNA. But cellular DNA is not perfect, because of spontaneous oxidation, hydrolysis, alkylation, strand breaks and so on. As many as 300,000 such lesions may occur every day in every cell of a human body, most of which are dealt with by special repair systems. Each unrepaired lesion is a potentially lethal event that can stop the regular DNA-replication machinery. However, SOS, a class of unusual DNA polymerases, allows DNA replication to proceed despite the lesions.
Errors and infidelity, even wastefulness, can cause individual failure, but also provide innovation and robustness, ensuring the perpetuation of life. Nature does not exhaust itself for the sake of fidelity and perfectionism. Rather, errors are made, often repaired or discarded, but always tested as the source of blind innovation during the continuous adaptation to unpredictable environmental changes and challenges.”
At this juncture, Professor Astin may then want a deeper explanation of just how physics influences chemical bonds and in turn alters genetic sequences. The short answer to this is found in the latest research in how quantum mechanics and evolution intertwine. High energy cosmic rays, for instance, can alter a single atom's location within a chemical strand and thereby induce an unexpected mutation. Quantum decoherence has of late been a ripe field of study for those interested in figuring out how cancer cells arise and mutate.

All of this, of course, is happening on a physical level (even if at incredibly small scales) and doesn't necessitate a Creator God or an Intelligent Designer. Therefore what may seem to be a large “gap” turns out on closer inspection not to be one, especially given the consilience of quantum theory with molecular biology, something that was not lost on Erwin Schrodinger when he prophetically predicted in his now famous book, What is Life? (1944), that the secret to biology should be explained by physics and chemistry. As Professor Jimal-Khalili of the University of Surrey elaborates in his blog "Quantum-biology" (July 23, 2010),
“… At such scales, even quantum mechanics would play a role. He [Schrodinger] also introduced the idea of an “aperiodic crystal” that contained genetic information in its configuration of covalent chemical bonds. It was this book that one of the discoverers of DNA, Frances Crick, claimed was his inspiration.
So does quantum mechanics play a role within the cell? On one level, we have to say that it must. After all, the molecules of life are held together in the same way as any molecule: through chemical bonds subject to the rules of the quantum world. What is far more interesting is whether the weirder features of quantum mechanics also play a role. One obvious one is quantum tunnelling (the subatomic equivalent of walking through walls). This is just one of the areas currently being studied by a new breed of researchers who straddle the boundary between quantum physics and microbiology.”
In closing, I think Professor Astin and other like-minded doubters in evolution should be applauded for their skepticism because it allows those proffering evidence for molecular biology to up their game. I realize that for many professional scientists this may be an unwarranted intrusion on their busy lives (where the evidence seems overwhelming and obvious), but the fact remains that if a proposition is indeed true, and can withstand vigorous disagreement, its veridicality will illuminate all the more, especially as it reflects on other misplaced attempts, like creationism, to overthrow it.
While science may indeed confront impasses in its quest for underlying truths (and at times these may temporarily seem like holes large enough to drive a hummer through), this doesn't mean that we need to prematurely resort to a God of the Gaps explanation. Sometimes if we dig a little deeper, research a bit farther, and don't fall prey to Paul Kurtz's “transcendental temptation,” we will find a scientific explanation for what hitherto appeared inexplicable.
REFERENCES
Al-Khalili, J. (2010). Quantum Biology, http://www.jimal-khalili.com/blog/quantum-biology.html
Diem-Lane, A. (2008). Darwin's DNA: A Brief Introduction to Evolutionary Philosophy, www.integralworld.net
Pray, L. (2008) DNA replication and causes of mutation. Nature Education 1(1)
Radman, M. (2001), Fidelity and infidelity, Nature 413, 115
|